2 Prologsysteme
- 2 Prologsysteme 7
- 2.1 Entwicklung von Prolog 7
- 2.1.1 Systčme-Q 7
- 2.1.2 Prolog 0 8
- 2.1.3 Prolog und Logik 10
- 2.2 Vergleich der Spracheigenschaften 10
- 2.2.1 Referenzielle Transparenz 10
- 2.2.2 Metasprachlichkeit 11
- 2.2.2.1 Prolog 12
- 2.2.2.2 Funktionale Sprachen 12
- 2.2.2.3 Imperative Sprachen 12
- 2.2.2.4 Maschinensprachen 12
- 2.3 Prologs Implementierungsmodell 13
- 2.3.1 Deterministisches Prolog 13
- 2.3.2 Nichtdeterministisches Prolog 13
- 2.4 Anforderungen an die Speicherverwaltung 13
- 2.4.1 Zeitliches Speichermodell 14
- 2.4.2 Flüchtige Datenstrukturen 14
- 2.4.2.1 Implementierungskosten 14
- 2.4.2.2 Beispiele 16
- 2.4.2.2.2 Metainterpreter 16
- 2.4.2.2.2 Matrizenmultiplikation 18
- 2.4.2.2.3 Sortieren 18
- 2.4.2.3 Unterstützung des Programmierstils 19
- 2.4.3 Permanente Datenstrukturen 19
- 2.4.4 Redundante Darstellung 20
2 Prologsysteme
In diesem Kapitel wird die geschichtliche Entwicklung der Programmiersprache
Prolog kurz angerissen, um dann auf die Probleme bei der Implementierung
einzugehen. Es wird auf die für Prolog und wenige andere Programmiersprachen
charakteristische Eigenschaft der referenziellen Transparenz eingegangen, und
gezeigt, wie dadurch der Programmierer unterstützt wird. Das typische
Implementierungsmodell für Prolog wird vorgestellt und die Notwendigkeit einer
Speicherbereinigung neben der Verwaltung über Stacks begründet. Beispiele, die
zeigen, wann eine Verwaltung mittels eines heaps und einer dazugehörigen
Speicherverwaltung einen klareren Programmierstil unterstützt, werden
vorgestellt. Dabei wird sich herausstellen, daß man hier einerseits mit sehr
kurzlebigen -flüchtigen (volatile, transient)- und andereseits mit permanenten
Datenstrukturen zu rechnen hat. Die Anforderungen an eine Speicherbereinigung
werden hierauf formuliert.
2.1 Entwicklung von Prolog
Prolog (programmation en logique) stellt eine besonders einfache Vereinigung
vieler Konzepte, die Ende der 60-er Jahre diskutiert wurden, dar. Auf der einen
Seite sind Forschungsergebnisse im Bereich der Logik, Kowalskis Vereinfachung
von Robinsons Resolution, auf der anderen Seite praktische
Implementierungstechniken aus Bereichen des Übersetzerbaus Pate gestanden.
Colmerauer, der über Jahre mit der Implementierung von Compilern beschäftigt
war, erkannte die Mächtigkeit der von van Wijngaarden entwickelten W-Grammatik.
W-Grammatiken können Typ 0 Sprachen erzeugen und damit implizit jede Berechnung
darstellen. Bestechend an den W-Grammatiken ist, daß man durch Regeln eine
möglicherweise nichtdeterministische Berechnung darstellen kann. Colmerauer
verwendete diesen Formalismus probehalber zur Übersetzung von französischen und
englischen Sätzen [ChaCo69]. Ein Problem der W-Grammatiken stellt ihre
aufwendige Implementierung dar.
In der Folge entwickelte er Systčme-Q, das als der Vorgänger von Prolog
bezeichnet werden kann. Hier wurden bereits das Berechnen in mehrere Richtungen
und Nichtdeterminismus, aber noch nicht die Unifikation realisiert. Nicht
unähnlich von Chomsky Typ 0 Grammatiken konnten Terme umgeformt werden. Damit
hatte Colmerauer unabhängig von den Entwicklungen innerhalb der formalen Logik
ein System geschaffen, das schon fast alle Eigenschaften von Prolog enthält.
Auch heute noch werden in Kanada mit diesem System englische Wetterberichte ins
Französische übersetzt.
Erst nach dieser Entwicklung (1970) erfuhr Colmerauer in Marseille von den
Arbeiten Robinsons. Mit Phillipe Roussel entwickelte er den Begriff der
formellen Gleichheit für die Unifikation. Dadurch galt für Terme nicht mehr das
Assoziativgesetz, dafür ließ sich die Unifkation aber wesentlich effizienter
realisieren. Kowalski hatte sich, als reiner Logiker, die Einbindung des Axioms
der Assoziativität in die Horn-Klauseln noch vorgestellt. In [Kowa88]
beschreibt Kowalski die Entwicklungen jener Zeit. Auch wenn diese Eigenschaft
gerade für Zeichenfolgen elementar ist, wurde erst in den letzten Jahren diese
Idee wieder aufgegriffen [ComLe88 und Referenzen]. Colmerauer überarbeitete sein
Systčme Q vollständig, um es in Einklang mit den Formalismen der Logik zu
bringen. Anstatt der Produktionen ähnlich den Typ 0 Grammatiken in Systčme Q
wurden Horn-Klauseln verwendet. Eine Horn-Klausel ist entweder eine Klausel
eines definiten Programms oder ein definites Ziel [Llo87]. Horn Klauseln
besitzen maximal ein positives Literal. Vom Standpunkt der Grammatiken aus
betrachtet wurden dadurch die Produktionen kontextfrei, während in Typ 0
Grammatiken auch kontextabhängige Produktionen verwendet werden können. Die
Ausführung eines Programms entspricht nun dem Beweisen eines definiten Ziels
unter Verwendung der SLD-Resolution (Linear resoultion with Selection function
of Definite clauses). Colmerauer entschied sich für eine Selektionsfunktion mit
Tiefensuche und die der Auswahl der Literale nach ihrer Ordnung in einer Klausel
von links nach rechts. Dadurch war es möglich, eine sehr effiziente
Implementierung, die den Prozeduraufrufen in herkömmlichen Sprachen ähnelt, zu
realisieren.
Hornklauseln:
A :-
B1,...,Bn Klausel eines definiten Programms,
:- B1,...,Bn Definites Ziel
keine Hornklausel:
:- A1,A2 , B1,...,Bn
Die erste Prolog-Implementierung -Prolog 0- wurde von Phillipe Roussell im Jahre
1971 in Algol W fertiggestellt. 1972 wurde das erste größere Prologprogramm,
eine natürlichsprachige Schnittstelle, in Prolog 0 entwickelt. Prolog 0 besaß
bereits ein sicheres Prädikat zur Feststellung der formellen Ungleichheit (
dif/2 ), das erst jetzt, abgesehen von den Prologsystemen aus Marseille, wieder
Eingang in neuere Prologsysteme findet. In Prolog 0 kann man noch viel
deutlicher als im heutigen Prolog die Beziehung zu den Horn-Klauseln erkennen.
Positive und negative Literale werden durch ein Vorzeichen unterschieden.
+VATER(PETER,PAUL) ;;
+MUTTER(MARIA,JAKOB) ;;
+GATTE(PETER,MARIA) ;;
+BRUDER(*Z,*Y) -VATER(*X,*Y ) -VATER(*X,*Z) -DIF(*Y,*Z) ;;
+VATER(*X,*Z) -GATTE(*X,*Y) -MUTTER(*Y,*Z) ;;
Anfrage: -BRUDER(PAUL,*X) / +ANTWORT(*X) ..
Antwort: +ANTWORT(JAKOB) ;.
Prolog 0- Programm
Beim Beweis eines Programms wurden ausgehend von der Anfrage stets ein negatives
Literal (das Ziel) mit einem positiven Literal (Kopf einer Klausel) unifiziert,
und durch die negativen Literale dieser Klausel (Rumpf) ersetzt. Ziele, die
nicht direkt bewiesen werden konnten -etwa -DIF(*Y,*Z)- wurden in der Liste der
negativen Literale (Zielliste) belassen. Dadurch konnte auf einfache aber nicht
sehr effiziente Weise das Aufschieben von Zielen und damit eine sichere
Implementierung des dif/2 realisiert werden. Insofern war dieser Interpreter
schon wesentlich fortgeschrittener als die meisten heutigen Systeme. Die
Arbeitsweise eines Prologinterpreters läßt sich also wie folgt schematisch
darstellen:

In der weiteren Folge wurde Prolog vor allem durch eine große Menge von
vordefinierten Prädikaten erweitert. Der eigentliche Mechanismus wurde nicht
mehr verändert. Durch die Übersetzungstechnik von D.H.D. Warren [Warr77,Warr83]
konnte Prolog mit ähnlicher Effizienz wie andere symbolische Sprachen
implementiert werden. Dadurch waren die Voraussetzungen für einen breiteren
Einsatz von Prolog gegeben. Auf der anderen Seite entdeckten immer mehr
Forscher, die zuvor an dem bis heute noch immer nicht erreichten Ziel der
automatischen Verfikation imperativer Programme gearbeitet hatten, die Schönheit
von Prolog, das bis zu einem gewissen Grad nur mehr die Zusicherungen
(assertions) aber nicht mehr die dazwischenstehenden obskuren imperativen
Programmteile, darstellt. Prolog wurde so bei einer immer größer werdenden
Gruppe von Theoretikern populär, die erkannten, daß sie nur in diesem Rahmen,
dem Bereich der Logik-Programmierung, theoretische Erkenntnisse rasch in die
Praxis umsetzen konnten, ohne dabei allzu lange mit den Implementierungsdetails
ihrer Ideen aufgehalten zu werden. Der Begriff der Unifikation etwa, der sich in
Prolog nur auf einfache Terme bezieht, ist eine Hintertür, um in Prolog noch
weitere interessante Gleichungssysteme zu verwenden. So wurde in Marseilles
mittlerweile Prolog III entwickelt, das auch Gleichungen über rationale Zahlen
lösen kann. Allgemein gehören diese Erweiterungen zum sog. CLP-Schema
(Constraint Logic Programming) [JaLa87]. Prolog stieß in viele Bereiche der
theoretischen Informatik, etwa der algebraischen Spezifikation [GoMe87] oder der
Programmtransformation [Hog81] vor, in denen praktische Implementierungen rasch
verwirklicht werden können.
Trotz des theoretischen Umfelds, das Prolog umgibt; der Logik-Programmierung,
konnte Prolog auch in anderen Bereichen der Informatik, etwa beim VLSI-Entwurf
seine Verwendbarkeit beweisen. Anwendungen, die aus dem Bereich der künstlichen
Intelligenz -dem ursprünglichen Anwendungsgebiet von Prolog- stammen, vor allem
Expertensysteme und die Verarbeitung natürlicher Sprache dürfen natürlich nicht
unerwähnt bleiben. Die Verwendung von Prolog hat sich, ausgehend von einigen
Universitäten und vielen Pionieren, in den letzten fünf Jahren auf den
industriellen Bereich ausgedehnt, sodaß seit Frühjahr 1988 an einer
internationalen Prolog-Standardisierung innerhalb der ISO SC22 WG17 [Der89]
gearbeitet wird.
2.1.3 Prolog und Logik
Immer wieder wird vor allem von theoretischer Seite her kritisiert, daß Prolog
eine zu einfache Berechnungsstrategie besitzt, die bei der Konstruktion des
SLD-Beweisbaumes nicht immer alle Lösungen finden kann. Auch Negation kann nur
in beschränktem Ausmaß verwendet werden;.Betrachtet man Prolog aus der
geschichtlichen Perspektive, so ist dies gar nicht verwunderlich: Prolog ist
primär das effizient implementierbare Produkt eines Übersetzerbauers und nicht
Derivat aus der formalen Logik. Systeme, die Beweise finden, gab es schon in den
60-er Jahren; keines dieser Systeme fand aber wegen der enormen Ineffizienz
jemals weitere Verbreitung. Prolog ist hingegen eine Programmiersprache, mit der
man mit ähnlichem Aufwand wie in prozeduralen Sprachen arbeitet. Systeme, die
eine faire Berechnungsstrategie verwenden, können in Prolog mit minimalem
Programmieraufwand realisiert werden.
Prolog hat also mit Prädikatenlogik nur sehr wenig zu tun. Aber vielleicht hat
sich Philippe Roussel nur verhört, als seine Frau in einem Zug zwischen Paris
und Marseille den Namen Prolog erfand und Prolog steht in Wirklichkeit für
programmation la logique.
2.2 Vergleich der Spracheigenschaften
Im folgenden werden einige unbestrittene Eigenschaften von Prolog im Vergleich
mit anderen Programmiersprachen hervorgestrichen. Um Prolog auf gleicher Ebene
mit ihnen zu messen, werden nur jene Aspekte erwähnt, die auch in anderen
Programmiersprachen Eingang gefunden haben oder finden sollten.
2.2.1 Referenzielle Transparenz
Der Begriff der referenziellen Transparenz wurde anfänglich im Bereich der
Funktionalen Sprachen, wie Hope [Fie88] geprägt. Dort versteht man darunter,
daß ein Funktionsausdruck unabhängig vom Zeitpunkt seiner Interpretation stets
denselben Wert hat. Auf imperative Programmiersprachen übertragen müßten die
Objekte der Sprache auch unabhängig von ihrem Kontext bzw. Sichtbarkeits-/
Gültigkeitsbereich (scope) als ein Wert verstanden werden können. Referenzen auf
Werte (z.B. Variablen) können im Gegensatz dazu in Programmiersprachen mit
vorwiegend imperativem Programmierstil (z.B. Pascal, Lisp) nur aufgrund ihres
zeitlichen Verhaltens -ihrer Geschichte- verstanden werden; derartige Sprachen
werden daher auch referentiell opak genannt. In einem prozeduralen Programm
verletzt selbst ein simples Programm wie "x := expr; x := x + 1;" die
Transparenz der dargestellten Werte, da hier der zeitliche Zustand einer
Variable zum Verständnis des Programms benötigt wird. Insbesondere ist es in
einer prozeduralen Sprache unmöglich, direkt auf einen früheren Wert einer
Variable zuzugreifen. Wenn man in einem prozeduralen Programm "sicher" mit
Werten arbeiten will, muß man sie bei jeder Änderung vollständig
kopieren. Typisch dafür sind etwa Stringmanipulationen in C mittels strcpy. Es
gibt kaum imperative Programmiersprachen, bei denen man sich bemüht hätte,
diese unangenehme Eigenschaft auf die notwendigsten Bereiche zu beschränken.
Eine der wenigen Ausnahmen stellt hier CLU [LisGu86] dar: Durch eigene
unveränderbare Datentypen können applikativen Sprachen ähnliche Objekte
verwendet werden. Anstatt einer herkömmlichen Zuweisung wird ein neues
verändertes Objekt geschaffen. Für den Fall, daß zeitliche Übergänge durch die
Problemstellung zu modellieren sind, sollten zumindest Abstrakte Datentypen,
die u.U. algebraisch beschrieben werden können, verwendet werden. Bezogen auf
Prolog können wir den Begriff der referentiellen Transparenz ebenso verwenden.
Es ergeben sich hier allerdings einige Unterschiede zu den rein Funktionalen
Sprachen.
- Objekte können noch "unvollständig" sein, d.h. Variablen enthalten. Im
Gegensatz zu imperativen Sprachen gibt es durch das Konzept der Unifikation für
Prologs Variablen eine klare Semantik. Prolog wird deshalb auch single
assignment Sprache genannt. Dadurch wird ein Großteil der destruktiven
Operationen, wie sie etwa in Lisp vorhanden sind (REPLACA u.ä.) hinfällig. D.H.D
Warren und Fernando und Luis Pereiras haben als erste diesen Vorteil deutlich
herausgestrichen [WarP77]. Tatsächlich gibt es kein einziges kommerzielles
Prologsystem, das zu REPLACA analoge Operationen erlaubt. Auch der ISO-Vorschlag
für einen Prologstandard blieb bisher [Der89] von derartigen Unterwanderungen
der referentiellen Transparenz verschont. Offensichtlich kann also das Konzept
der logischen Variablen von Prolog die destruktiven Operationen (Zuweisungen)
effizient genug ersetzen.
- Prolog-Programme können während der Ausführung des Programms verändert werden.
Es ist dadurch zwar möglich, Zuweisungen imperativer Programmiersprachen zu
simulieren, insofern wäre Prolog ebenso referentiell opak wie herkömmliche
Programmiersprachen; durch die sog. logical update view [LiKe87] kann allerdings
ein Großteil der unvorhersehbaren Seiteneffekte vermieden werden. Ganz abgesehen
davon existieren die Programme zudem völlig unabhängig von den dynamischen
Daten. Durch assert/2 kann ausschließlich die Datenbank manipuliert werden.
Insofern entspricht assert/2 eher dem DEFUN oder SETQ von LISP. Der Vergleich
dieser Elemente mit imperativen Programmiersprachen ist zudem nicht
gerechfertigt, da jene ja keinen Übersetzer für die Sprache selbst als
Sprachmittel besitzen und dennoch referentiell opak sind. Bei einem System, das
sehr lange Zeit existiert, müssen Fähigkeiten zur Selbstverwaltung, ähnlich wie
in Betriebssystemen, vorhanden sein.
2.2.2 Metasprachlichkeit
Unabhängig davon, welche Sprache wir sprechen oder verwenden, können wir uns
sicher sein, daß wir durch neues Wissen eine bessere oder einfachere
Beschreibungsform, daher eine neue Sprache, benötigen werden. Dies ist ein
üblicher Prozeß, der eine Stufe weiterer Erkenntnis in der neuen Sprache zum
Ausdruck bringt. In allen Lebensbereichen und Wissenschaften entstehen so neue
Sprachen, die einer gezielten Kommunikation dienen. Dies gilt auch für
Beschreibungssprachen in der Informatik. Wichtig erscheint es daher, neue
Sprachen mit möglichst geringem Aufwand beschreiben und implementieren zu
können. So, wie die Alltagssprache zur Einführung in eine Wissenschaftssprache
verwendet wird, sollten auch Programmiersprachen die Definition von mächtigeren
oder spezialisierteren Programmiersprachen ermöglichen. Damit hätten wir
zugleich auch eine verwendbare Implementierung der neuen Sprache.
Metasprachliche Abstraktionen ermöglichen die Definition, Implementierung von
Sprachen; die Bearbeitung ganz allgemein (etwa Erklärung, Analyse). Ein gutes
Maß zur Abschätzung, der Eignung einer Sprache zur Verwirklichung von
metasprachlichen Abstraktionen, stellt die Realisierung der Sprache -insbesondere
der Programmiersprache- durch sich selbst dar. Dadurch kann man auch Sprachen
ganz unterschiedlicher Ebenen auf ihren Anspruch, eine general purpose language
zu sein, untersuchen. Wenn es in einer Sprache nur sehr schwer möglich ist, sich
selbst zu beschreiben, wird es auch sehr schwer möglich sein, essentielle
Erweiterungen für sie zu finden. Da Programmiersprachen selbst formal definiert
werden, wird man meist den Abstrakten Syntaxbaum als Ausgang dieser Untersuchung
verwenden.
In Prolog wird der Abstrakte Syntaxbaum eines vorhandenen Programms klauselweise
mittels clause/2 erzeugt. Mittels sog. Metainterpreter wird dieser Struktur eine
deklarative bzw. operationale Semantik gegeben. Diese Technik wird in Prolog
ausgiebig [StSh86] verwendet. Unter einem Metainterpreter versteht man in der
Tradition der Logikprogrammierung ein Programm, das eine ähnliche Sprache
ausführt, in der das Programm geschrieben worden ist. In weiterer Folge spricht
man hier auch von meta-level architectures, in [Har88] findet sich eine aktuelle
Klassifikation über die möglichen konzeptuellen Ausprägungen. Man kann zudem in
Prolog zwischen verschiedenen Ebenen der Beschreibung wählen. Für gewisse
Anwendungen wird man etwa nur die Klauseln in einer anderen Reihenfolge
interpretieren wollen, nur die Unifikation verändern oder neue Datentypen
einführen wollen. Je weiter man Prolog durch sich selbst beschreibt, umso
komplexer wird diese Darstellung werden. Zumeist kommt man aber mit dem
dreizeiligen Grundgerüst aus. Eine komplette Beschreibung wird aber auch in
Prolog eine entsprechende Größe besitzen. Die vollständige Spezifikation von
Prolog in Hornklauseln mit Negation [Der87a] umfaßt momentan zirka 70
ausführlich mit Beispielen kommentierte Seiten [Der89].
2.2.2.2 Funktionale Sprachen
In diesem Bereich hat sich für dasselbe Konzept, insbesondere in der
Scheme-Tradition [Abe85], die Bezeichnung metacircular evaluator eingebürgert.
Neuere Funktionale Programmiersprachen unterstützen aber kaum metasprachliche
Abstraktionen. Offensichtlich waren ihre Erfinder der Meinung, damit bereits
genügend mächtige Sprachen implementiert zu haben.
2.2.2.3 Imperative Sprachen
Da die Struktur von herkömmlichen imperativen Programmiersprachen von den
sprachlichen Möglichkeiten dieser Programmiersprachen her nur sehr schwer erfaßt
werden kann, gibt es kaum praktisch verwendete Realisierungen von
metasprachlichen Abstraktionen. Es wäre zwar denkbar, den Syntaxbaum der Sprache
als eigenen Datentyp einzuführen, die Operationen auf derartigen Strukturen sind
aber durch des Fehlen referentieller Transparenz extrem fehleranfällig. Nur in
ADA hat man versucht, den Abstrakten Syntaxbaum einheitlich zu beschreiben
[Go83,Ros85,Ze]. Zeigermanipulationen können, da sie meist nicht durch einen
Abstrakten Datentyp geschützt sind, bei einem syntaktisch richtigen Programm zu
einer undefinierten Operation führen. Selbst bei der Definition derartiger
Programmiersprachen zog man es lieber vor, eine neue Sprache -mit referentieller
Transparenz- eigens zur Beschreibung zu entwickeln (z.B. VDL für PL 1 [Oll71 und
Referenzen], W-Grammatik für Algol68 [Wij75]), als die Sprache durch sich selbst
zu beschreiben. Daraus kann man ersehen, wie groß die Kluft zwischen der
ungenügenden Mächtigkeit der Sprachmittel und der ausufernden Fülle von
semantischen Details ist. Die einzige verwendete Realisierung metasprachlicher
Konzepte stellen symbolische Debugger dar. Hier möchte man auch in imperativen
Programmiersprachen den Ablauf des Programms durch ein anderes Programm erklärt
bekommen.
2.2.2.4 Maschinensprachen
Bei den Instruktionsformaten von Prozessoren findet der Abstrakte Syntaxbaum
seine Entsprechung. Das Verhältnis zwischen Sprachmitteln und Semantik kann hier
wieder als verhältnismäßig ausgeglichen bezeichnet werden. So benötigt Knuth zur
Beschreibung seiner Maschinensprache MIX in MIX selbst 311 Assemblerzeilen
[Knu73]. Knuth bezeichnet ein derartiges Programm als Simulator. Auch die
Bezeichnung Emulator wird häufig verwendet. Emulatoren werden zur
Implementierung des Verhaltens eines Prozessors auf einem anderen eingesetzt.
Zur Messung gewisser Leistungsmerkmale (Speicherdurchsatz, Lokalität etc.) für
einen konkreten geplanten Prozessor dienen ebenfalls derartige Programme.
2.3 Prologs Implementierungsmodell
Das im folgenden vorgestellte Implementierungsmodell wird als eine Erweiterung
des in prozeduralen Sprachen üblichen Speichermodells motiviert. In fast allen
Implementierungen von Prolog wird dieses Modell verwendet.
2.3.1 Deterministisches Prolog
Betrachtet man rein deterministische Programme, so ist der Kontrollfluß von
Prolog vergleichbar mit dem einer Prozeduralen Sprache. Man benötigt aso einen
Stack um die Aufrufshierarchie und lokale Werte zu verwalten. Die Variablen von
Prolog haben aber keine Entsprechung in einer prozeduralen Sprache. Durch die
Unifikation kann einer Variable nicht nur ein Wert zugewiesen werden; freie
Variablen können auch aneinander gebunden werden. Solange keine
zusammengesetzten Terme verwendet werden, kann man die Variablen aber lokal, in
ihrem Environment am sog. Environmentstack darstellen. Da die Größe von
zusammengesetzten Termen erst zur Laufzeit bestimmt werden kann, müssen sie in
einem eigenen Bereich, dem Copystack (WAM-Terminologie: heap), dargestellt
werden. Auch in Prozeduralen Sprachen, etwa Algol 68 [Bran71] oder CLU [LiGu86]
werden Strukturen mit dynamischer Größe so dargestellt. Diese Strukturen, deren
Lebenszeit mit der Gültigkeit des Prozedur- bzw. Environmentstacks nicht
übereinstimmen muß, müssen von einer eigenen Speicherbereinigung reorganisiert
werden.
2.3.2 Nichtdeterministisches Prolog
Nichtdeterministische Programme, zum ersten Mal von Floyd [Flo67] als
Erweiterung von Algol 60 implementiert, müssen bei jedem Wahlpunkt
(choicepoint) den Zustand der Maschine "einfrieren". Da Prolog die vor einem
Wahlpunkt erzeugten Datenstrukturen nur mittels Unifikation verändern kann, und
dabei nur Variablen gleichsetzen, oder durch Terme instanzieren kann, muß man,
im Gegensatz zu Floyds Ansatz, der bei jeder Zuweisung den alten Wert einer
Variable speichern muß, nur die gebundenen Variablen registrieren. In den
Wahlpunkten müssen die Größen der Stacks und die offenen Alternativen, sowie der
davor liegende Wahlpunkt gespeichert werden. Die Wahlpunkte werden gemeinsam mit
den Environments auf dem Environmentstack verkettet gespeichert. Am
Environmentstack befindet sich somit genau der Teil des Beweisbaumes, von dem
aus der restliche, noch nicht besuchte Teil erreicht werden kann. Um das
Wiedererfüllen eines Ziels (backtracking) effizient zu unterstützen, werden die
Bindungen auf einem eigenen Stack, dem Trail, registriert.
2.4 Anforderungen an die Speicherverwaltung
Die Implementierung von VIP kann bereits alle für die Speicherverwaltung der
Kontrollstrukturen erforderlichen Operationen implizit durch seine abstrakte
Maschine (VAM [Kral87]) durchführen. Nur die Verwaltung des Copystacks muß
mittels einer eigenen zusätzlich zum Interpreter und zur abstrakten Maschine
existierenden Speicherbereinigung realisiert werden. Es werden nun einige
Anforderung an diese Speicherverwaltung formuliert werden, um die in Kapitel 3
vorgestellten Verfahren auf ihre Eignung zu überprüfen.
2.4.1 Zeitliches Speichermodell
In allen Systemen, in denen Objekte verwaltet werden müssen, kann man unabhängig
von einer konkreten Implementierung der Speicherbereinigung eine Klassifizierung
der Objekte nach ihrer Lebensdauer, also der Zeit wie lange das Objekt benötigt
wird, vornehmen. Ungar [Un88] hat hier im Umfeld von Smalltalk eine
Klassifizierung vorgenommen, die auch für Prolog anwendbar ist. Man betrachtet
hier die Lebenszeit von Objekten bezogen auf zwei beliebige Zeitpunkte während
der Laufzeit des Systems.

In einer konkreten Realisierung wird zu den beiden Zeitpunkte GC1 und GC2 eine
Speicherbereinigung die nicht mehr benötigten Objekte entfernen. Eine
charakteristische Eigenschaft der Verfahren ist ihre Abhängigkeit von diesen
vier Klassen. Es stellt sich bei den meisten Systemen heraus, daß man vor allem
mit einer großen Menge von flüchtigen (transient) und permanenten
Datenstrukturen zu rechnen hat. Je älter ein Objekt ist, umso eher wird es auch
weiterexistieren. Je nach Wahl der Größe des Intervalls kann man die neu
hinzukommenden Objekte (arrival objects) und die nicht mehr referenzierten
Objekte zu einer dieser Klassen zuordnen.
2.4.2 Flüchtige Datenstrukturen
Gelegentlich kann die Lebensdauer von flüchtigen Datenstrukturen bereits aus der
Problemstellung bzw. dem Programm erkannt werden. In einigen Fällen wird man
daher versuchen, flüchtige Datenstrukturen direkt durch einen Stack
darzustellen. Dennoch kann man bei genügend großem Speicher zeigen, daß auch die
Realisierung eines Stacks unter der Annahme, daß für jede push- und
pop-Operation eine konstante Zeitspanne benötigt wird, mittels flüchtiger
Datenstrukturen und einer von der Anzahl der flüchtigen Datenstrukturen
unabhängigen Speicherbereinigung eine effizientere Implementierung ergibt.
2.4.2.1 Implementierungskosten
Eine Speicherbereinigung mittels eines Kopieralgorithmus (siehe Kapitel 3.3.6)
kostet abhängig von der Anzahl A der erreichbaren Zellen (c +ds)A. Sie ist also
unabhängig von der Anzahl der nichtreferenzierten Zellen bzw. von der Größe des
gesamten Speichers M. Unter der Annahme, daß die Anzahl der erreichbaren Zellen
zum Zeitpunkt jeder GC gleich bleibt, können die Kosten pro Zelle, die für sie
benötigte Zeit pro GC berechnet werden. Falls die Speicherbereinigung erst
eingesetzt wird, wenn bereits der gesamte Speicher aufgebraucht ist, so ist die
Anzahl der zwischen zwei Speicherbereinigungen allokierten Zellen gleich G:

Die Kosten pro Zelle g daher:

Zum Anlegen einer Zelle benötigen beide
Implementierungen eines Stacks gleich viel Zeit. Die Freigabe eines Elements auf
einem traditionell implementierten Stack benötigt die Zeit f. Bei einer
Speicherverwaltung mit Speicherbereinigung ist keinerlei Mehraufwand
erforderlich. Die beiden Versionen werden also unter folgenden Bedingungen den
gleichen Aufwand pro angelegter Zelle benötigen:

Falls also M/sA größer als (c +
ds)/f +1 gemacht werden kann, wird eine Speicherbereinigung effizienter als eine
Stackverwaltung sein. Bei den Annahmen von [Appel 87] muß der Speicher 8 mal
größer als die Anzahl der verwendeten Elemente sein. Bei einer Verdopplung der
momentanen Speichergröße, werden sich die Kosten bei M >> A also halbieren!
G ............. Anzahl der Zellen, die zwischen zwei GC angelegt werden.
A ............. Anzahl der erreichbaren Zellen
M ............. Größe des vorhandenen Speichers
c ............. Aufwand pro Zelle
d ............. Aufwand pro Zeiger
s ............. Zellgröße
g ............. Kosten pro Zelle
f ............. Kosten für eine pop-Operation
Andrew Appel [Appel 87] begründet so, daß es zur Unterstützung von applikativen
Sprachen wesentlich interessanter ist, mehr Speicher zur Verfügung zu haben,
als durch spezielle Hardware oder aufwendige Analysen des Compilers den
Prozessor beim Anlegen von Speicherelementen zu unterstützen. Die einzige
Voraussetzung ist, daß die Speicherbereinigung unabhängig von der Anzahl der
flüchtigen Datenstrukturen ist. Natürlich können durch eine derartige
Speicherverwaltung möglicherweise sehr lange Pausen entstehen. Adaptive
Verfahren, bei denen ähnlich Annahmen für ihren Aufwand gelten, werden in
Kapitel 3.3.6.3 vorgestellt. Der Vergleich ist natürlich nur dann zulässig,
wenn pro pop-Operation tatsächlich zumindest eine Zeit von f > 0 benötigt wird.
Bei der Speicherverwaltung von Prolog ist es allerdings noch immer interessant,
das in Kapitel 2.3 vorgestellte Implementierungsmodell zu verwenden. Durch die
zeitliche Abhängigkeit der Datenstrukturen in Prolog kann man bei backtracking
größere Teile des Stacks sofort freigeben. Man kann also pro pop-Operation mit
einem wesentlich geringeren Aufwand rechnen, der nicht mehr proportional zur
Anzahl der freigegebenen Elemente ist. Deswegen kann daher durch einen größeren
Speicher wohl nie diese Effizienz erreicht werden. Dennoch experimentiert man
auch in Prolog mit derartigen Konfigurationen [Bek84, Bek86]. Für die Verwaltung
der Speicherzellen am Copystack gilt allerdings allgemein, daß ihre Kosten durch
eine Vergrößerung des Speichers reduziert werden können.
Flüchtige Datenstrukturen werden gerade auf neueren Systemen, die mit
Daten-caches ausgestattet sind, sehr effizient unterstützt: Bei ihrer Erzeugung
werden sie, da dadurch auf Speicherzellen geschrieben, aber nicht gelesen wird,
im cache angelegt. Es erfolgt keinerlei Zugriff auf den eigentlichen
Hauptspeicher. Während der kurz auf ihre Erzeugung folgenden Verwendung werden
sie sich noch immer im cache befinden. Es ist daher nicht erforderlich, sie
aus dem Hauptspeicher einzulesen. Erst lange nach ihrer Verwendung werden die
flüchtigen Datenstrukturen in den Hauptspeicher hinausgeschrieben werden, da der
Prozessor nunmehr auf anderen Speicherzellen arbeitet (cache flush). Bei
größerem cache (ab ca. 64K) kann man sogar erwarten, daß die
Speicherbereinigung, falls sie sich nur auf einen kleineren Bereich des
Arbeitsspeichers bezieht, die "toten" Strukturen noch immer im cache antrifft.
Der eigentliche Mehraufwand liegt so nur mehr in der Speicherbereinigung, die
dafür verantwortlich ist, daß sich die Maschine bezüglich des paging des
virtuellen Speichers noch immer lokal verhält.
Es wird nun anhand des einfachsten Metainterpreters gezeigt, wie hier flüchtige
Datenstrukturen, die von der Speicherbereinigung verwaltet werden müssen,
anfallen. Dieser Metainterpreter kann nur eine Untermenge von Prolog
verarbeiten, vordefinierte Prädikate müßten gesondert behandelt werden.
solve(true).
solve((X,Y)) :-
solve(X),
solve(Y).
solve(X) :-
clause(X,Y),
solve(Y).
Damit dieser Interpreter zumindest auch sich selbst interpretieren kann, müßte
clause/2 sich wie folgt verhalten:
clause(H,B) :-
H \= clause(_,_),
real_clause(H,B).
clause(clause(H,B),B) :-
real_clause(H,B).
p(X,X).
p(X,Z) :-
q(X,Y),
p(Y,Z).
q(a,b).
Während des Beweisens von :- p(X,b). durchläuft der Prologinterpreter den
entsprechenden SLD-Baum:
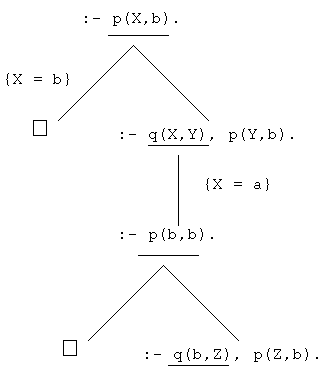

Beweis mittels Prolog-Resolution und die durch den
Metainterpreter angelegten Strukturen zum Zeitpunkt der zweiten gefundenen
Lösung
Der Metainterpreter wird nun bei :- solve(p(X,b)). all jene Ziele als
Datenstrukturen durch clause/2 erzeugen, die von der Anfrage aus zu dem
aktuellen Knoten führen. Dabei werden nur bei Regeln Strukturen erzeugt. Eine
direkte Ausführung des Programms hätte nur einen einzigen Wahlpunkt mit den
dazugehörigen Variablen erzeugt. Die neu angelegten Strukturen ,/2 und q/2
werden für die nachfolgenden Berechnungen nicht mehr benötigt. Verglichen mit
der direkten Ausführung wird sich daher der Platzbedarf bei folgenden Elementen
unterscheiden:
Die Kontrollstruktur ,/2 wird im Prologinterpreter durch structure sharing der
Darstellung der Klauseln realisiert, d.h. daß die gleichbleibenden Teile einer
Klausel nur einmal in der Datenbasis dargestellt werden. Die sich ändernden
Teile, also die Variablen werden gesondert abgespeichert. Der Metainterpreter
muß diese Struktur aber bei jedem neuen Ziel erzeugen. Die aktuellen Ziele
werden durch den Prologinterpreter mit Hilfe des Environmentstacks realisiert.
Der Metainterpreter muß auch hier jedes einzelne anfallende Ziel als Term im
Copystack besitzen. Das Stackframe einer deterministischen Klausel kann bei
Aufruf des letzten Ziels durch lastcall-Optimierung entfernt werden. Der
Metainterpreter hat hier direkt keine Entsprechung. Allerdings können sämtliche
angefallenen Kontrollstrukturen, insofern sie nicht mehr wegen eines Wahlpunktes
benötigt werden, durch die Speicherbereinigung entfernt werden. Dabei kann der
Metainterpreter sogar mehr Elemente entfernen als dies bei einem
Prologinterpreter der Fall ist: Der Prologinterpreter muß jedes Environment als
eine Einheit behandeln. Wenn also bereits gewisse Variablen darin nicht mehr
benötigt werden, könnte der Prologinterpreter sie höchstens freigeben, falls
diese am "Rand" des Environments vorkommen. Bei der WAM (siehe unten) wird
dieser Vorgang stack trimming genannt. Im Gegensatz dazu muß der Metainterpreter
nur die einzelnen Ziele als Strukturen verwalten; die Variablen werden dadurch
implizit mitverwaltet. Der Metainterpreter könnte im besten Fall in Bezug auf
die Größe des Environmentstacks um einen von der Größe des Programms abhängigen
Faktor weniger Platz als das direkt exekutierte Programm verbrauchen.
In diesem Beispiel wurde gezeigt, wie die Speicherbereinigung für einen
Metainterpreter den Großteil der typischen Prolog-Optimierungen nachvollzieht.
2.4.2.2.2 Matrizenmultiplikation
Flüchtige Datenstrukturen treten nicht nur in der Rolle von Kontrollstrukturen,
sondern auch als Zwischenergebnisse einer Berechnung, auf. Da wir uns auf ein
kleines Beispiel beschränken wollen, das genau jenen Fall aufzeigt, wo flüchtige
Datenstrukturen auftreten, wurde ein eher funktionales Programm gewählt. Bei
nichtdeterministischen Programmen ist es ja wesentlich schwieriger, flüchtige
Datenstrukturen, die nach erfolgter Berechnung noch am Copystack verbleiben, zu
erzeugen, da ja bei Wiedererfüllung eines Ziels (backtracking) ohnehin die
Zwischenergebnisse durch die Anordnung am Stack wegfallen.
Der übliche Ansatz, Programme zu entwickeln, zerlegt ein Problem in
Teilprobleme, die sich zum Teil rekursiv formulieren lassen. Im Unterschied zu
Prozeduralen Sprachen kann aber in applikativen Sprachen das Teilproblem
vollkommen unabhängig von der eigentlichen Aufgabe verstanden werden.
Zwischenergebnisse oder Parameter können, falls sie bereits bekannt sind, nicht
mehr verändert werden. Falls Zwischenergebnisse noch nicht Teil des
Endergebnisses sind, werden sie nach erfolgter Berechnung nicht mehr benötigt.
Hier fallen dann flüchtige Datenstrukturen, die durch eine Speicherbereinigung
erkannt werden müssen, an.
Es soll etwa die Multiplikation von zweidimensionalen Matrizen implementiert
werden. Matrizen seien durch Listen von Listen dargestellt, die zeilenweise die
Matrix darstellen. Die Anfrage
:-
matrix_multiply([[3,5],[2,9]],[[6,2],[7,1]],M). sollte M = [[53,11],[75,13]]
liefern. Die Zeilen der ersten Matrix sollen mit den Spalten der zweiten für
alle Kombinationen errechnet werden. Da es aber nicht direkt möglich ist, die
zweite Matrix spaltenweise zu bearbeiten, müßte man ein komplexeres Verfahren
entwickeln. Innerhalb der Implementierung einer Bibliothek von Vektor- und
Matritzenoperationen seien nun bereits mehrere Prädikate implementiert worden,
etwa transpose/2 zur Transponierung einer Matrix...
transpose(M,[]) :-
nullrows(M).
transpose(M1,[Row|M2]) :-
makerow(M1,Row,M3),
transpose(M3,M2).
makerow([],[],[]).
makerow([[X|R1]|M1],[X|Row],[R1|M2]) :-
makerow(M1,Row,M2).
nullrows([]).
nullrows([[]|M]) :-
nullrows(M).
:- transpose(L,[[6,2],[7,1]]).
L = [[6,7],[2,1]].
... sowie das Skalarprodukt zweier Vektoren:
dot_prod([],[],0).
dot_prod([X|Xs],[Y|Ys],S) :-
dot_prod(Xs,Ys,T),
S is T + (X * Y).
Mittels dieser beiden Prädikate kann bei der Multiplikation von Matrizen eine
transponierte Matrix verwendet werden, um Zeilen und Spalten mit dem
Skalarprodukt zu kombinieren.
matrix_multiply(MA,MB,MR) :-
transpose(MB,TB),
mul_rows_cols(MA,TB,MR).
mul_rows_cols([],_,[]).
mul_rows_cols([X|M1],T,[Y|M2]) :-
mul_onerow_cols(T,X,Y),
mul_rows_cols(M1,T,M2).
mul_onerow_cols([],_,[]).
mul_onerow_cols([Col|Cols],Row,[El|Els]) :-
dot_product(Col,Row,El),
mul_onerow_cols(Cols,Row,Els).
Die transponierte Matrix L = [[6,7],[2,1]] bildet das flüchtige Zwischenergebnis
erzeugt durch das Unterziel :-transpose([[6,2],[7,1]],L). Dieses
Zwischenergebnis stellt einen typischen Fall für eine flüchtige Datenstruktur
dar: Direkt, nachdem sie erzeugt worden ist, wird sie für einige wenige
Operationen verwendet. Nach mul_rows_cols/3 wird diese Datenstruktur nicht mehr
benötigt. Natürlich könnte das Erzeugen des Zwischenergebnisses in diesem
Beispiel durch entsprechende Programmtransformation umgangen werden; bei diesem
Beispiel wäre etwa fusion [Fea87] angebracht.
Bei der Entwicklung größerer Programme kann man aber nur sehr lokal die
Techniken der Programmtransformation anwenden -allein schon wegen der komplexen
Analysen. Falls die vorhandenen Datenstrukturen den Zugriff auf die gewünschten
Elemente nicht nur, wie in diesem Beispiel, komplizieren, sondern auch
wesentlich ineffizienter machen, etwa weil die Elemente bei jedem Zugriff in
einem Baum gesucht werden müssen, ist es naheliegend, Zwischenergebnisse zu
verwenden. Als Beispiel sei hier das Sortieren einer Liste genannt. Auch in
Prolog verwendet man häufig das zu quicksort analoge Programm.
quicksort([],L,L).
quicksort([Key|List],Tail,Sort) :-
partition(Key,List,L1,L2),
quicksort(L2,Tail,Between),
quicksort(L1,[Key|Between],Sort).
partition(Key,[],[],[]).
partition(Key,[E|L],[E|L1],L2):-
E =< Key,
!,
partition(Key,L,L1,L2).
partition(Key,[E|L],L1,[E|L2]) :-
partition(Key,L,L1,L2).
Man hat hier nicht nur mit einem Aufwand n log n mit n der Anzahl der
Elemente der Liste zu rechnen, sondern auch mit zirka n ld n Listenelementen
als flüchtige Zwischenergebnisse; im worst case mir n2. Natürlich kann man auch
in Prolog ohne unnötige Zwischenergebnisse eine Liste mittels dem bekannten
Prädikat slowsort/2 sortieren:
slowsort(L,K) :-
permutation(L,K),
ordered(K).
Hier ist es wohl offensichtlich, daß flüchtige Datenstrukturen als
Zwischenergebnisse, die schlimmstenfalls einen Mehraufwand von n2 für die
nachfolgende Speicherbereinigung bedeuten, sehr gerne in Kauf genommen werden.
2.4.2.3 Unterstützung des Programmierstils
Speicher für kurzlebige Datenstrukturen unterstützen applikative
Programmiersprachen. Flüchtige Datenstrukturen übernehmen häufig Aufgaben von
Programmen in herkömmlichen Programmiersprachen: Sie "steuern" den eigentlichen
Programmablauf. In der einfachsten Variante, beim Arbeiten mit Listen,
übernehmen sie oft die Aufgabe von Iteratoren. Anstatt z.B. eine for Schleife zu
programmieren, wird eine Operation auf alle Elemente einer Liste angewendet. Für
den Programmierer entfallen dadurch die Definition und Verwaltung der
Schleifenvariablen. Die Programme werden so von redundanten
Kontrollinformationen befreit, die Information des eigentlichen Ablaufes bleibt
lokal in den Datenstrukturen. Die (syntaktisch) schönsten Beispiele dafür finden
sich in funktionalen Programmiersprachen, wie etwa Hope. Aber auch in Prolog
wird diese Technik, verallgemeinert auf beliebige u.U. unendliche Bäume
[Colm82], verwendet.
Durch die verbesserten Möglichkeiten neuerer imperativer
Programmiersprachen bei der Unterstützung von Datenabstraktion können
etwa Iterationen auch dort einfacher realisiert werden. Grenzen werden
aber durch die strenge zeitliche Folge der Instruktionen gesetzt. CLU
stellt hier die konsequenteste Realisierung dar, aber auch in ADA
können derartige Iterationen klar dargestellt werden.
2.4.3 Permanente Datenstrukturen
Permanente Datenstrukturen treten primär bei sehr langlebigen Systemen etwa
Datenbanksystemen auf. Objekte, die die Zeitdauer einer Applikation überleben,
werden persistent genannt. Für sie sollte möglichst eine andere
Speicherbereinigung als für die flüchtigen Datenstrukturen realisiert werden.
Bezogen auf die Copystackverwaltung in Prolog werden alle vor einem Wahlpunkt
angelegten Datenstrukturen zumindest bis zur Wiedererfüllung (backtracking)
dieser Alternative benötigt. Eine Speicherbereinigung für den Copystack sollte
daher auf diese Eigenschaft Rücksicht nehmen.
2.4.4 Redundante Darstellung
In Kapitel 2.3 wurde das übliche Implementierungsmodell für Prolog vorgestellt,
dabei wurde angenommen, daß jeder Term durch eine konkrete Datenstruktur
realisiert werden muß. In den ersten Implementierungen hat man daher versucht
durch structure sharing die unveränderbaren Teile, die bereits in den Klauseln
erkannt werden können, nur genau einmal darzustellen. Auch in einer
Implementierung durch structure copying kann durch eine Komprimierung der
redundanten Darstellungen der Copystack beträchtlich reduziert werden.
Voraussetzung für diese Erweiterung einer konventionellen Speicherbereinigung
ist die referentielle Transparenz der Terme. In Prolog hat man keine Möglichkeit
zwei Terme, die identisch sind, für die also das Ziel :- X == Y. erfüllt ist,
voneinander zu unterscheiden, obwohl sie eine unterschiedliche Repräsentation
besitzen können. Es gibt auch kein Prologsystem, das ein vordefiniertes Prädikat
zur Feststellung der tatsächlichen Repräsentation ermöglicht. Prologterme können
daher unabhängig von ihrer zeitlichen Entwicklung repräsentiert werden. Man kann
etwa nach der erfolgreichen Unifikation von zwei Termen mit einer
unterschiedlichen Repräsentation nur eine der beiden Repräsentationen
weiterverwenden.